The first order of business was to put our knowledge in order and supplement it. There is no better knowledge source than the official ITU-T standard defining the H264 codec: "Advanced video coding for generic audiovisual services." It might be overwhelming - the standard consists of 680 pages of printed text written in an ultra technical manner, however, for our needs, we could skip the parts concerning the video encoding and decoding processes - which make up most of the standard's volume.
AVC, H.264 or MPEG-4 p. 10?
Firstly, we would like to explain the nomenclature that we will be using, since it might be misleading. The codec, or more precisely - a coding standard, that we are describing is known under three names:
- AVC - that stands for: Advanced Video Coding
- H.264 - the name is derived from the name of ITU-T (International Telecommunication Union Standardization Sector) (recommendation)[https://www.itu.int/rec/T-REC-H.264] that defines that coding standard
- MPEG-4 Part 10 - the name is derived from the name of a (document)[https://www.mpeg.org/standards/MPEG-4/10/] defining the standard, prepared by the ISO/IEC JTC 1 (Joint Technical Committee (JTC) of the International Organization for Standardization (ISO) and the International Electrotechnical Commission) Moving Picture Experts Group
The existence of multiple names originates from the fact that the codec has been standardized as a cooperation of two groups - Video Coding Experts Group of ITU-T and Moving Picture Experts Group of ISO/IEC JTC 1. Within the text of the article we will most frequently use the "H.264" name, as it is most commonly used.
Why do we use H.264?
There are multiple reasons! The most important is that it allows us to represent video in a format that:
- supports compression - compression happens on multiple levels (for more information about some "tricks" used to compress the images and video, we invite you to read a tutorial published on our website):
- chroma subsampling - the compression standard, which takes advantage of the imperfections of human perception and removes the information about the pixels' color that the human's eye can't even process
- DCT (discrete cosine transform) and rounding it's coefficients to the integers
- intra-frame prediction - each video frame is divided into so called "macroblocks" (square areas consisting of 16x16 pixels) and instead of storing the information about all the pixels of each frame, only information of all of the pixels for some frames is stored (these are so called "keyframes"), and the rest of the frames are stored as vectors describing the translation of given macroblocks
- allows for convenient multimedia transport - it's easy to pack an H.264 stream into multimedia containers (i.e. MP4) or packets (like RTP packets) and send it via the internet.
It's good to be aware that in fact the H.264 stream is designed to be wrapped in some other data structure, like a multimedia container (i.e. MP4) or some transport protocol packets (i.e. RTP packets) - we shouldn't store the H.264 stream as a plain binary file, as it might lead to many problems. The reason for that is that the H.264 stream itself does not contain all of the information that is required for a video to be properly displayed. Examples of such information are timestamps - H.264 stream does not contain timestamps at all, so unwrapping the H.264 stream from the MP4 container (that contains timing information additionally) and storing just the H.264 stream leads to a loss of information.
However, that's just theory - in practice, tools like FFmpeg allow you to read the plain H.264 files and do some "best effort" approximations of the missing information - i.e. when the framerate of the video is constant, they can simply calculate the missing timestamps by multiplying the ordering number of the given video frame by the inversion of the framerate. That defines some kind of implicit "standard" of dealing with H.264 stream dumps, which we have also needed to take into consideration while working on our parser.
One might ask - why use H.264, when its successor, H.265 standard (known also as HEVC, which stands for high efficiency video compression) is already available. The answer is - because H.264 is still widely used and still there is a need to cope with H.264 streams that are delivered to our system. At the same time, starting using H.265 comes with a great number of benefits, as it:
- allows for a better compression ratio. For a given video quality, up to 50% of bandwidth can be saved with H.265, compared to H.264, which has non-negligible impact on the maintenance costs of a media processing infrastructure.
- supports up to 8K UHDTV (in contrast to H.264, which supports up to 4K).
- supports up to 300 FPS (in contrast to H.264, which supports up to 59.94 FPS)
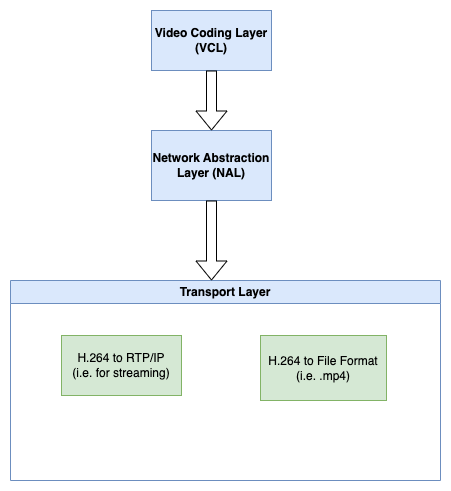
H.264 layers - VCL vs NAL
In H.264 two so-called "layers" can be distinguished:
- VCL (Video Coding Layer) - this layer deals mostly with the video compression standard. H.264 encoders and decoders need to work with that layer, but in the case of the H.264 parser, we won't need to dig into it.
- NAL (Network Abstraction Layer) - the layer that comes as a part of the network protocol's stack. It defines an abstraction over the VCL as it describes how the stream could be split into packets - Network Abstraction Layer units (we will refer to these units as NALu). Such an abstraction layer comes in handy for network devices i.e. it delivers information about how important a given packet is for the decoding process - based on that information, a network device knows which packets are high-priority and shouldn't be dropped (i.e. the ones that hold the keyframes), as dropping them would make the decoding impossible.
The NAL was the subject of our interest when it comes to the H.264 parser - the parser's goal is to read the NAL units and fetch the information that interested us out of them.