Redundancy removal
We learned that it's not feasible to use video without any compression; a single one hour video at 720p resolution with 30fps would require 278GB*. Since using solely lossless data compression algorithms like DEFLATE (used in PKZIP, Gzip, and PNG), won't decrease the required bandwidth sufficiently we need to find other ways to compress the video.
* We found this number by multiplying 1280 x 720 x 24 x 30 x 3600 (width, height, bits per pixel, fps and time in seconds)
In order to do this, we can exploit how our vision works. We're better at distinguishing brightness than colors, the repetitions in time, a video contains a lot of images with few changes, and the repetitions within the image, each frame also contains many areas using the same or similar color.
Colors, Luminance and our eyes
Our eyes are more sensitive to brightness than colors, you can test it for yourself, look at this picture.
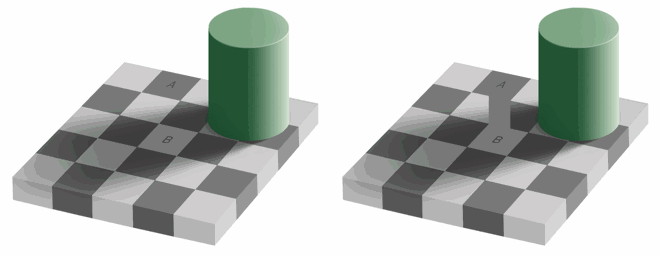
If you are unable to see that the colors of the squares A and B are identical on the left side, that's fine, it's our brain playing tricks on us to pay more attention to light and dark than color. There is a connector, with the same color, on the right side so we (our brain) can easily spot that in fact, they're the same color.
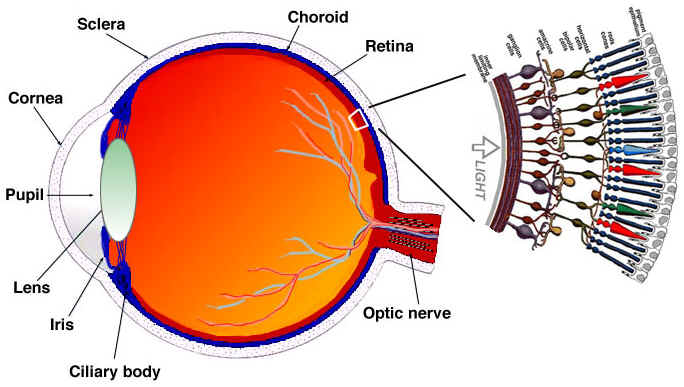
Simplistic explanation of how our eyes work The eye is a complex organ, it is composed of many parts but we are mostly interested in the cones and rods cells. The eye contains about 120 million rod cells and 6 million cone cells.
To oversimplify, let's try to put colors and brightness in the eye's parts function. The rod cells are mostly responsible for brightness while the cone cells are responsible for color, there are three types of cones, each with different pigment, namely: S-cones (Blue), M-cones (Green) and L-cones (Red).
Since we have many more rod cells (brightness) than cone cells (color), one can infer that we are more capable of distinguishing dark and light than colors.
Contrast sensitivity functions
Researchers of experimental psychology and many other fields have developed many theories on human vision. And one of them is called Contrast sensitivity functions. They are related to spatio and temporal of the light and their value presents at given init light, how much change is required before an observer reported there was a change. Notice the plural of the word "function", this is for the reason that we can measure Contrast sensitivity functions with not only black-white but also colors. The result of these experiments shows that in most cases our eyes are more sensitive to brightness than color.
Once we know that we're more sensitive to luma (the brightness in an image) we can try to exploit it.
Color model
We first learned how to color images work using the RGB model, but there are other models too. In fact, there is a model that separates luma (brightness) from chrominance (colors) and it is known as YCbCr*.
* there are more models which do the same separation.
This color model uses Y to represent the brightness and two color channels Cb (chroma blue) and Cr (chroma red). The YCbCr can be derived from RGB and it also can be converted back to RGB. Using this model we can create full colored images as we can see down below.
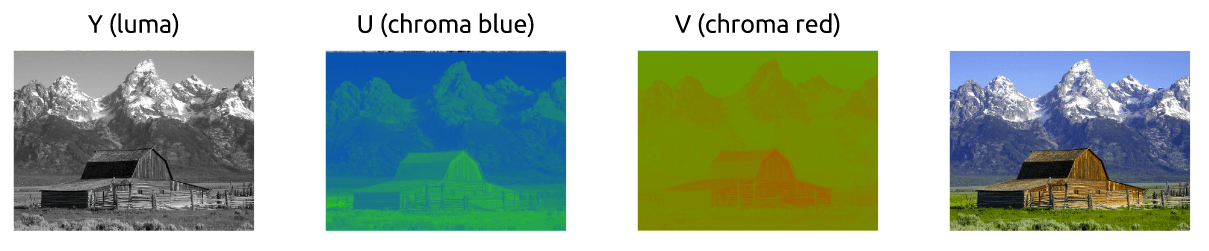
Converting between YCbCr and RGB
Some may argue, how can we produce all the colors without using the green?
To answer this question, we'll walk through a conversion from RGB to YCbCr. We'll use the coefficients from the standard BT.601 that was recommended by the group ITU-R* . The first step is to calculate the luma, we'll use the constants suggested by ITU and replace the RGB values.
Y = 0.299R + 0.587G + 0.114B
Once we had the luma, we can split the colors (chroma blue and red):
Cb = 0.564(B - Y) Cr = 0.713(R - Y)
And we can also convert it back and even get the green by using YCbCr.
R = Y + 1.402Cr B = Y + 1.772Cb G = Y - 0.344Cb - 0.714Cr
* groups and standards are common in digital video, they usually define what are the standards, for instance, what is 4K? what frame rate should we use? resolution? color model?
Generally, displays (monitors, TVs, screens and etc) utilize only the RGB model, organized in different manners, see some of them magnified below:
![]()
Chroma subsampling
With the image represented as luma and chroma components, we can take advantage of the human visual system's greater sensitivity for luma resolution rather than chroma to selectively remove information. Chroma subsampling is the technique of encoding images using less resolution for chroma than for luma.
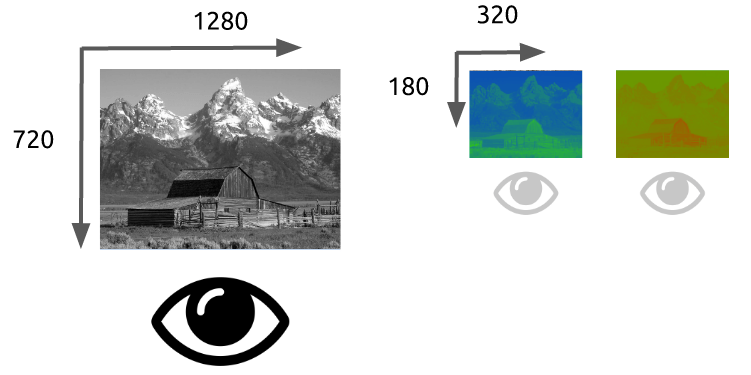
How much should we reduce the chroma resolution?! It turns out that there are already some schemas that describe how to handle resolution and the merge (final color = Y + Cb + Cr).
These schemas are known as subsampling systems and are expressed as a 3 part ratio - a:x:y which defines the chroma resolution in relation to a a x 2 block of luma pixels.
ais the horizontal sampling reference (usually 4)xis the number of chroma samples in the first row ofapixels (horizontal resolution in relation toa)yis the number of changes of chroma samples between the first and seconds rows ofapixels.
An exception to this exists with 4:1:0, which provides a single chroma sample within each
4 x 4block of luma resolution.
Common schemes used in modern codecs are: 4:4:4 (no subsampling), 4:2:2, 4:1:1, 4:2:0, 4:1:0 and 3:1:1.
You can follow some discussions to learn more about Chroma Subsampling.
YCbCr 4:2:0 merge
Here's a merged piece of an image using YCbCr 4:2:0, notice that we only spend 12 bits per pixel.
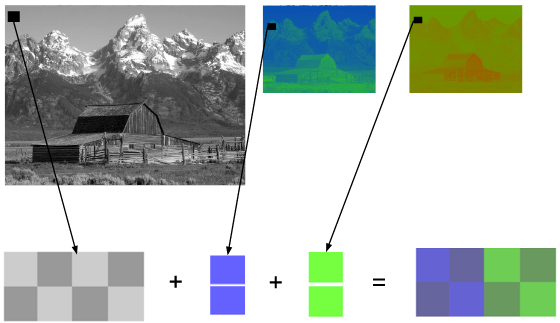
You can see the same image encoded by the main chroma subsampling types, images in the first row are the final YCbCr while the last row of images shows the chroma resolution. It's indeed a great win for such small loss.

Previously we had calculated that we needed 278GB of storage to keep a video file with one hour at 720p resolution and 30fps. If we use YCbCr 4:2:0 we can cut this size in half (139 GB)* but it is still far from ideal.
* we found this value by multiplying width, height, bits per pixel and fps. Previously we needed 24 bits, now we only need 12.
Hands-on: Check YCbCr histogram
You can check the YCbCr histogram with ffmpeg. This scene has a higher blue contribution, which is showed by the histogram.

Color, luma, luminance, gamma video review
Watch this incredible video explaining what is luma and learn about luminance, gamma, and color.

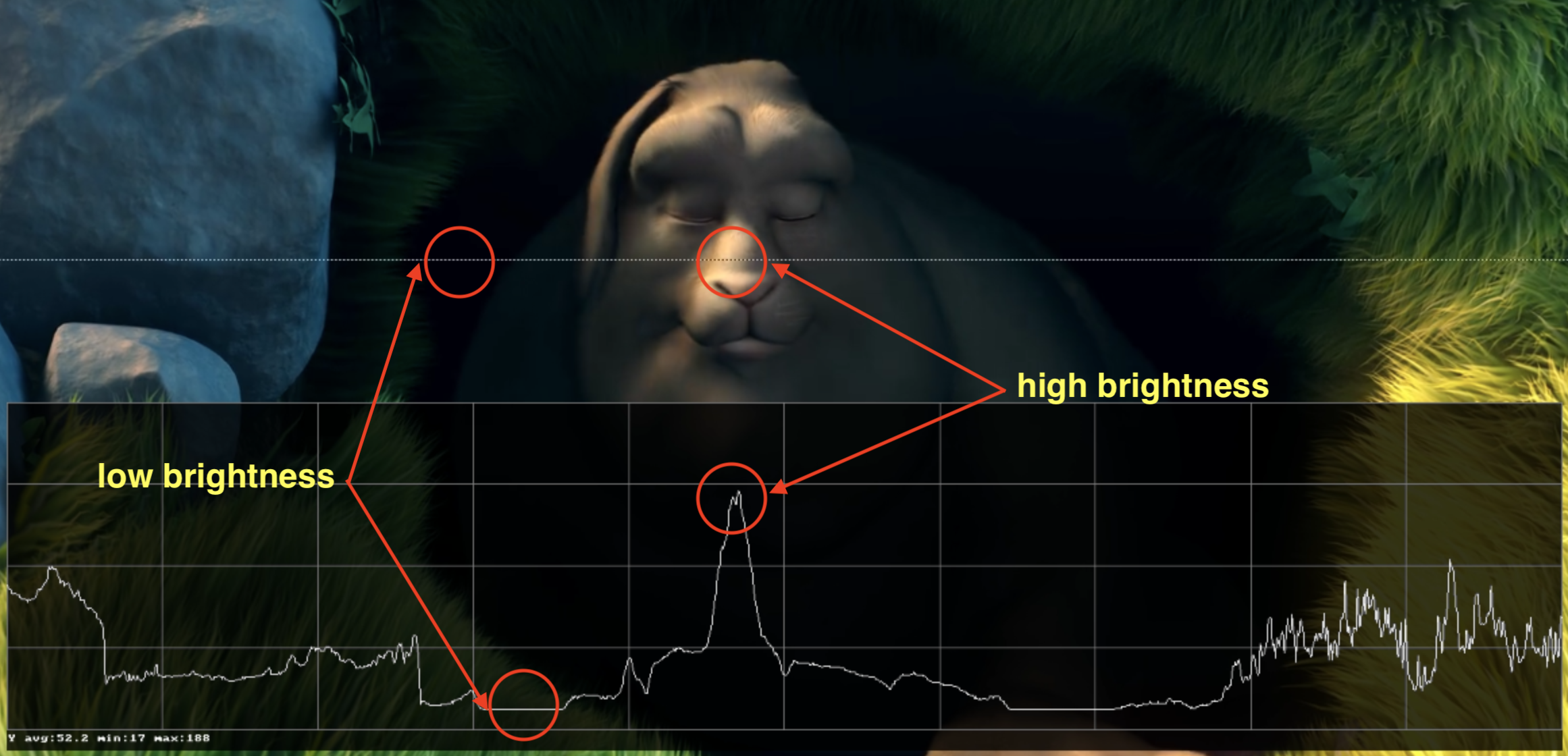
Hands-on: Check YCbCr intensity
You can visualize the Y intensity for a given line of a video using FFmpeg's oscilloscope filter.
ffplay -f lavfi -i 'testsrc2=size=1280x720:rate=30000/1001,format=yuv420p' -vf oscilloscope=x=0.5:y=200/720:s=1:c=1
Frame types
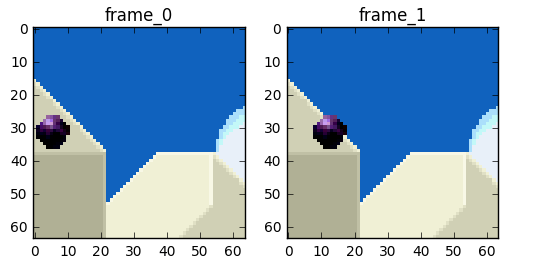
Now we can move on and try to eliminate the redundancy in time but before that let's establish some basic terminology. Suppose we have a movie with 30fps, here are its first 4 frames.




We can see lots of repetitions within frames like the blue background, it doesn't change from frame 0 to frame 3. To tackle this problem, we can abstractly categorize them as three types of frames.
I Frame (intra, keyframe)
An I-frame (reference, keyframe, intra) is a self-contained frame. It doesn't rely on anything to be rendered, an I-frame looks similar to a static photo. The first frame is usually an I-frame but we'll see I-frames inserted regularly among other types of frames.
P Frame (predicted)
A P-frame takes advantage of the fact that almost always the current picture can be rendered using the previous frame. For instance, in the second frame, the only change was the ball that moved forward. We can rebuild frame 1, only using the difference and referencing to the previous frame.
<- 
Hands-on: A video with a single I-frame
Since a P-frame uses less data why can't we encode an entire video with a single I-frame and all the rest being P-frames?
After you encoded this video, start to watch it and do a seek for an advanced part of the video, you'll notice it takes some time to really move to that part. That's because a P-frame needs a reference frame (I-frame for instance) to be rendered.
Another quick test you can do is to encode a video using a single I-Frame and then encode it inserting an I-frame each 2s and check the size of each rendition.
B Frame (bi-predictive)
What about referencing the past and future frames to provide even a better compression?! That's basically what a B-frame is.
<- ->
Hands-on: Compare videos with B-frame
You can generate two renditions, first with B-frames and other with no B-frames at all and check the size of the file as well as the quality.
Summary
These frames types are used to provide better compression. We'll look how this happens in the next section, but for now we can think of I-frame as expensive while P-frame is cheaper but the cheapest is the B-frame.

Temporal redundancy (inter prediction)
Let's explore the options we have to reduce the repetitions in time, this type of redundancy can be solved with techniques of inter prediction.
We will try to spend fewer bits to encode the sequence of frames 0 and 1.
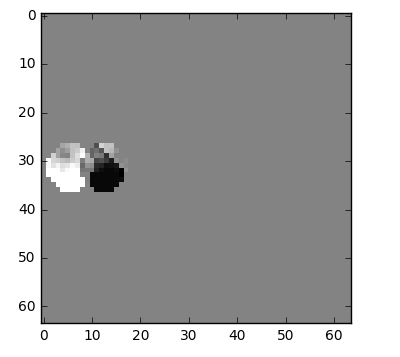
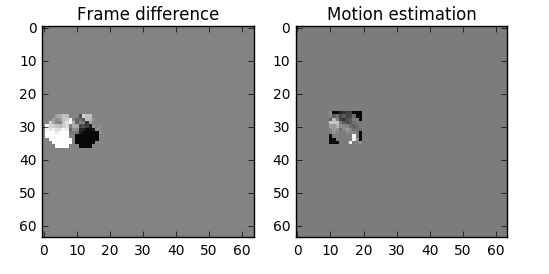
One thing we can do it's a subtraction, we simply subtract frame 1 from frame 0 and we get just what we need to encode the residual.
But what if I tell you that there is a better method which uses even fewer bits?! First, let's treat the frame 0 as a collection of well-defined partitions and then we'll try to match the blocks from frame 0 on frame 1. We can think of it as motion estimation.
Wikipedia - block motion compensation
"Block motion compensation divides up the current frame into non-overlapping blocks, and the motion compensation vector tells where those blocks come from (a common misconception is that the previous frame is divided up into non-overlapping blocks, and the motion compensation vectors tell where those blocks move to). The source blocks typically overlap in the source frame. Some video compression algorithms assemble the current frame out of pieces of several different previously-transmitted frames."
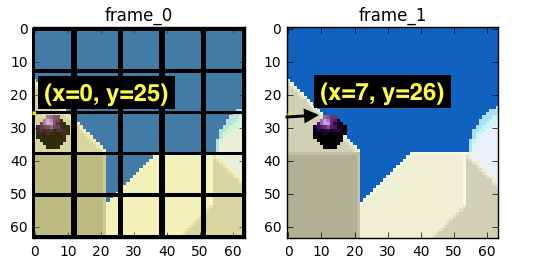
We could estimate that the ball moved from x=0, y=25 to x=6, y=26, the x and y values are the motion vectors. One further step we can do to save bits is to encode only the motion vector difference between the last block position and the predicted, so the final motion vector would be x=6 (6-0), y=1 (26-25)
In a real-world situation, this ball would be sliced into n partitions but the process is the same.
The objects on the frame move in a 3D way, the ball can become smaller when it moves to the background. It's normal that we won't find the perfect match to the block we tried to find a match. Here's a superposed view of our estimation vs the real picture.
But we can see that when we apply motion estimation the data to encode is smaller than using simply delta frame techniques.
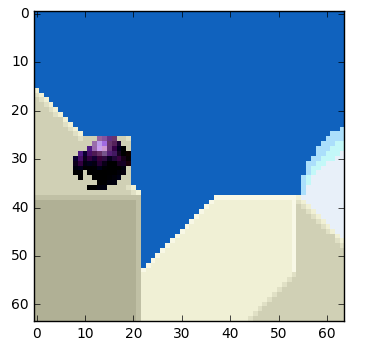
How real motion compensation would look
This technique is applied to all blocks, very often a ball would be partitioned in more than one block.
Source: https://web.stanford.edu/class/ee398a/handouts/lectures/EE398a_MotionEstimation_2012.pdf
You can play around with these concepts using jupyter.
Hands-on: See the motion vectors
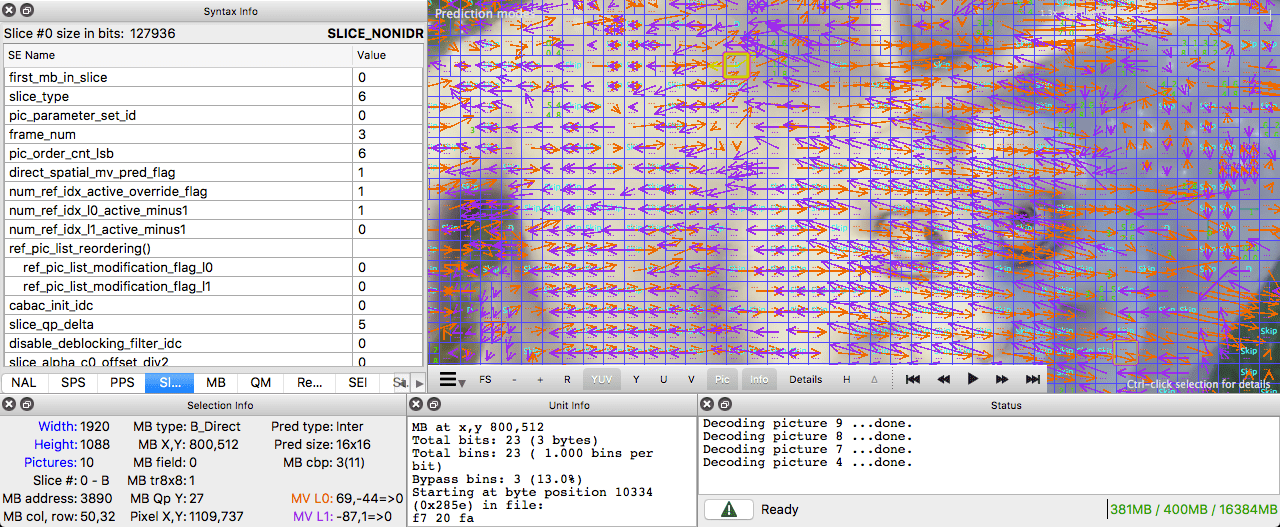
We can generate a video with the inter prediction (motion vectors) with ffmpeg.
Or we can use the Intel Video Pro Analyzer (which is paid but there is a free trial version which limits you to only work with the first 10 frames).

Spatial redundancy (intra prediction)
If we analyze each frame in a video we'll see that there are also many areas that are correlated.

Let's walk through an example. This scene is mostly composed of blue and white colors.

This is an I-frame and we can't use previous frames to predict from but we still can compress it. We will encode the red block selection. If we look at its neighbors, we can estimate that there is a trend of colors around it.

We will predict that the frame will continue to spread the colors vertically, it means that the colors of the unknown pixels will hold the values of its neighbors.
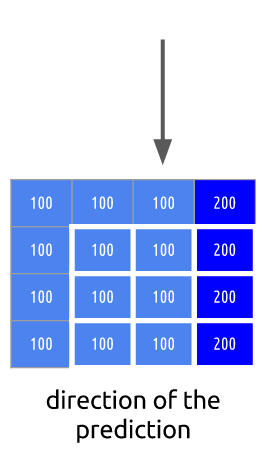
Our prediction can be wrong, for that reason we need to apply this technique (intra prediction) and then subtract the real values which gives us the residual block, resulting in a much more compressible matrix compared to the original.
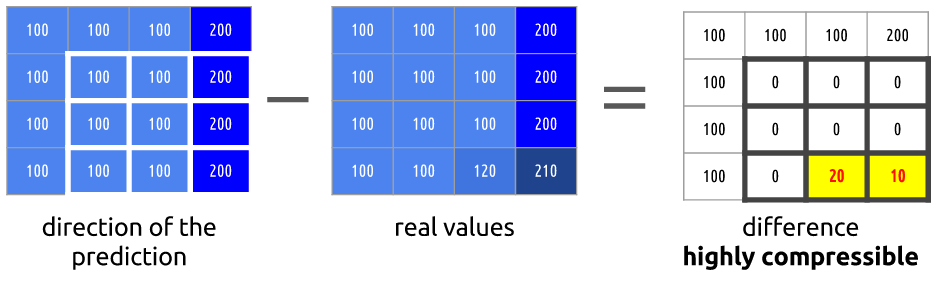
There are many different types of this sort of prediction. The one you see pictured here is a form of straight planar prediction, where the pixels from the row above the block are copied row to row within the block. Planar prediction also can involve an angular component, where pixels from both the left and the top are used to help predict the current block. And there is also DC prediction, which involves taking the average of the samples right above and to the left of the block.
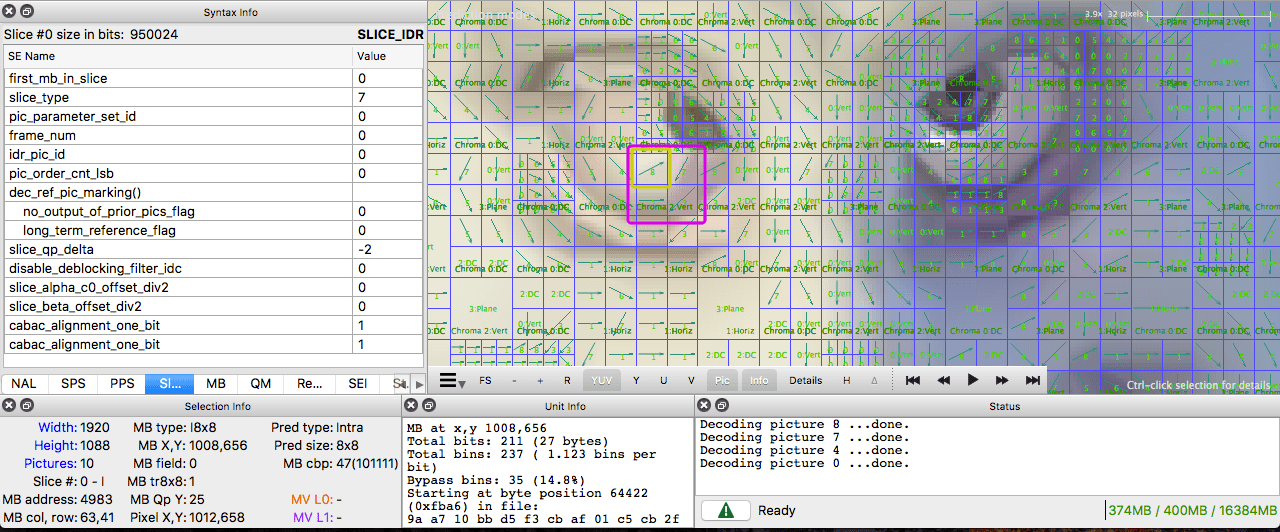
Hands-on: Check intra predictions
You can generate a video with macro blocks and their predictions with ffmpeg. Please check the ffmpeg documentation to understand the meaning of each block color.
Or we can use the Intel Video Pro Analyzer (which is paid but there is a free trial version which limits you to only work with the first 10 frames).

{kind=link}